152K+ 
Import Images
Drag and drop images to Supervisely, supported formats: .jpg, .jpeg, jpe, .mpo, .bmp, .png, .tiff, .tif, .webp, .nrrd

Connect your remote storage and import data without duplication. Data is stored on your server but visible in Supervisely
Drag and drop images to Supervisely, supported formats: .jpg, .jpeg, jpe, .mpo, .bmp, .png, .tiff, .tif, .webp, .nrrd
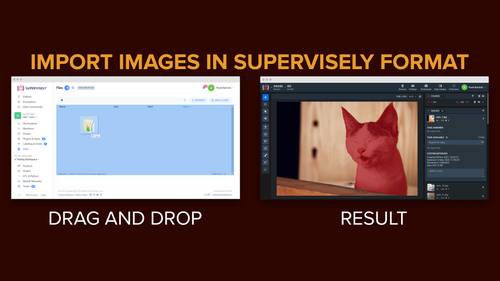
Images with corresponding annotations
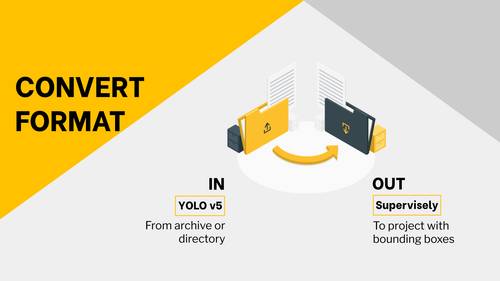
Transform YOLO v5 format to supervisely project

Upload images using .CSV file

Import images from cloud (Google Cloud Storage, Amazon S3, Microsoft Azure, ...)


